





ZLG深度解析——语音识别技术
3、回声消除
回声存在于双工模式时,麦克风收集到扬声器的信号,比如在设备播放音乐时,需要用语音控制该设备的场景。
回声消除通常使用自适应滤波器实现的,即设计一个参数可调的滤波器,通过自适应算法(LMS、NLMS等)调整滤波器参数,模拟回声产生的信道环境,进而估计回声信号进行消除。
4、混响消除
语音信号在室内经过多次反射之后,被麦克风采集,得到的混响信号容易产生掩蔽效应,会导致识别率急剧恶化,需要在前端处理。
混响消除方法主要包括:基于逆滤波方法、基于波束形成方法和基于深度学习方法等。
5、声源定位
麦克风阵列已经广泛应用于语音识别领域,声源定位是阵列信号处理的主要任务之一,使用麦克风阵列确定说话人位置,为识别阶段的波束形成处理做准备。
声源定位常用算法包括:基于高分辨率谱估计算法(如MUSIC算法),基于声达时间差(TDOA)算法,基于波束形成的最小方差无失真响应(MVDR)算法等。
6、波束形成
波束形成是指将一定几何结构排列的麦克风阵列的各个麦克风输出信号,经过处理(如加权、时延、求和等)形成空间指向性的方法,可用于声源定位和混响消除等。
波束形成主要分为:固定波束形成、自适应波束形成和后置滤波波束形成等。
2语音识别的基本原理
已知一段语音信号,处理成声学特征向量之后表示为,其中表示一帧数据的特征向量,将可能的文本序列表示为,其中表示一个词。语音识别的基本出发点就是求,即求出使最大化的文本序列。将通过贝叶斯公式表示为:
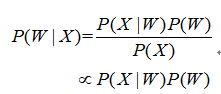
其中,称之为声学模型,称之为语言模型。大多数的研究将声学模型和语言模型分开处理,并且,不同厂家的语音识别系统主要体现在声学模型的差异性上面。此外,基于大数据和深度学习的端到端(End-to-End)方法也在不断发展,它直接计算 ,即将声学模型和语言模型作为整体处理。本文主要对前者进行介绍。
3声学模型
声学模型是将语音信号的观测特征与句子的语音建模单元联系起来,即计算。我们通常使用隐马尔科夫模型(Hidden Markov Model,HMM)解决语音与文本的不定长关系,比如下图的隐马尔科夫模型中。
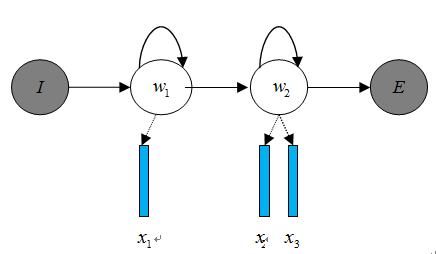
将声学模型表示为
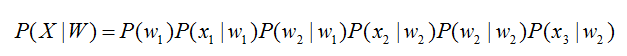
其中,初始状态概率和状态转移概率( 、 )可用通过常规统计的方法计算得出,发射概率( 、 、 )可以通过混合高斯模型GMM或深度神经网络DNN求解。
传统的语音识别系统普遍采用基于GMM-HMM的声学模型,示意图如下:

其中,表示状态转移概率,语音特征表示,通过混合高斯模型GMM建立特征与状态之间的联系,从而得到发射概率,并且,不同的状态对应的混合高斯模型参数不同。
基于GMM-HMM的语音识别只能学习到语音的浅层特征,不能获取到数据特征间的高阶相关性,DNN-HMM利用DNN较强的学习能力,能够提升识别性能,其声学模型示意图如下:
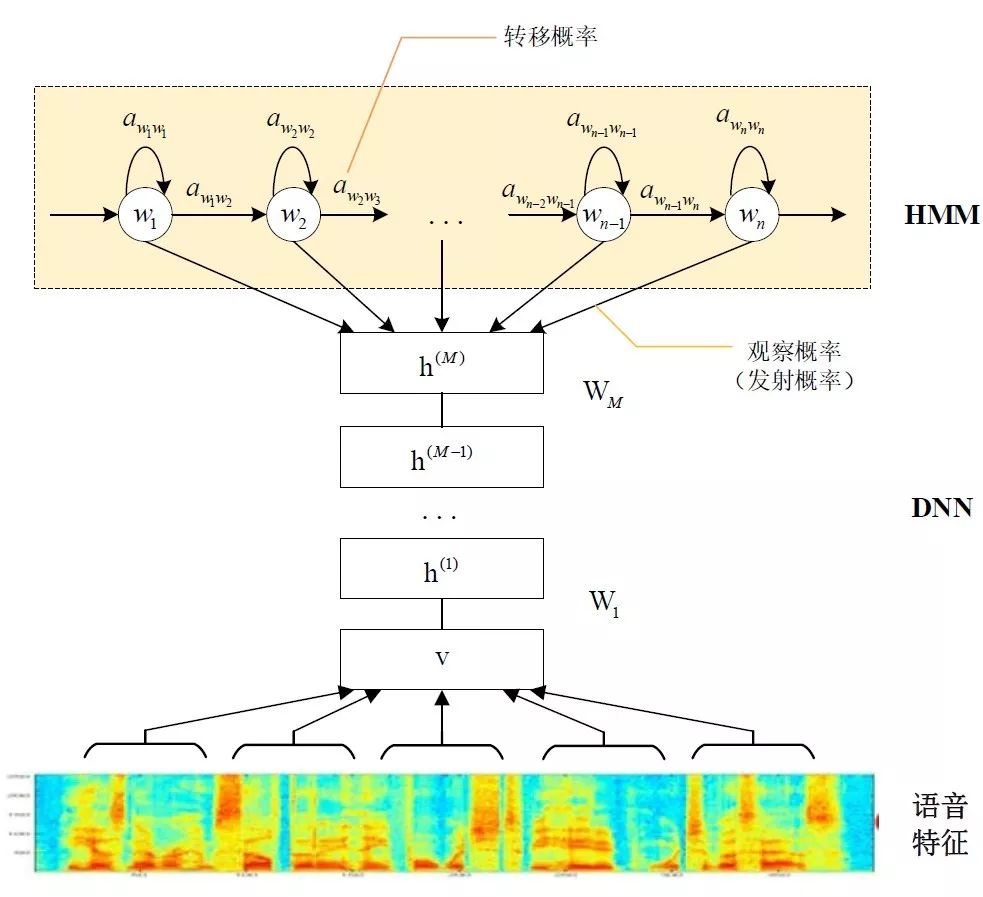
GMM-HMM和DNN-HMM的区别在于用DNN替换GMM来求解发射概率,GMM-HMM模型优势在于计算量较小且效果不俗。DNN-HMM模型提升了识别率,但对于硬件的计算能力要求较高。因此,模型的选择可以结合实际的应用调整。

 分享
分享
图片新闻




中国机器人产业大会圆满收官!")



最新活动更多
推荐专题

 中国机器人产业大会 暨维科杯机器人行业评选颁奖典礼")

国际无人机系统产业大会")
- 1 【独家深度】2025年中国机器人激光雷达行业市场调研
- 2 人形机器人革命,NVIDIA如何破局?
- 3 《2025机器人+应用与产业链新一轮加速发展蓝皮书》电子版限免下载!
- 4 用信步工控主板,当行业冠军,“天工”机器人马拉松夺冠!
- 5 MOONLIGHT 玄晖成为全球首款获得 CE+ETL双认证的力控型并联机器人
- 6 信步科技发布具身智能开发平台HB03,实现机器人“大、小脑融合”
- 7 【展商推荐】意优科技:专注于人形机器人关节模组的研发与生产
- 8 纤尘不染|新时达众为兴洁净型SCARA机器人新品重磅发布
- 9 MiR 发布最新电子书,揭示AMR 革新医院物流全流程
- 10 智同科技举行总部基地奠基仪式:以匠心筑基,与时代同行



发表评论
请输入评论内容...
请输入评论/评论长度6~500个字
暂无评论
暂无评论